

Translate this page into:
Toward a More Nuanced Interpretation of Statistical Significance in Biomedical Research
Address for correspondence Ram Bajpai, PhD, School of Medicine Keele University, Staffordshire ST5 5BG, United Kingdom. r.bajpai@keele.ac.uk
This article was originally published by Thieme Medical and Scientific Publishers Pvt. Ltd. and was migrated to Scientific Scholar after the change of Publisher.
Introduction
Statistical significance is the bedrock of evidence-based medicine, crucial for decision-making and framing biomedical science policies. The emergence of complex data in many disciplines, resulting from the analysis of large datasets, has amplified the popularity of p-values. Its simplicity allows investigators to conclude and disseminate their research findings in a manner understood by most. Thus, obtaining a p-value that indicates “statistical significance” against the null hypothesis is often required for publishing in medical journals. However, it creates challenges due to nonreproducibility, misuse and overinterpretation, which lead to serious methodological errors. This article aims to draw biomedical researchers' attention toward the appropriate use of p-values in clinical decision-making.
Historical Development
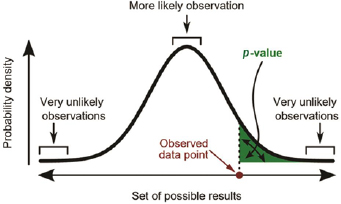
Fisher first introduced null hypothesis significance testing (NHST) in 1925.1 Subsequently, p-values became the standard of reporting and judging scientific evidence's strength when testing the null hypotheses against the alternative proposition in most scientific disciplines, including biomedical research. The recent development of big data research has made p-values even more popular to test the significance of study findings and has become a sine qua non for publishing in medical journals. The basis of the p-value is that it computes the probability of observing results at least as extreme as the ones observed, given that the null hypothesis is correct and compared against a predetermined significance level (α). If the reported p-value is lesser than α, the test result is to be considered statistically significant (Fig. 1). Typically, α is set arbitrarily at 0.05 level to control false-positive rate, and other commonly used significance levels are 0.01 and 0.001.
-
Fig. 1 Definition of p-value (https://en.wikipedia.org/wiki/Statistics).
Debate on Statistical Significance
Many researchers have questioned the acceptability of p-values in medical decision-making, and considerable research exists into how p-values are misused.2,3 For example, in his seminal paper, Cohen4 argued that: “NHST is highly flawed as it is relatively easy to achieve results that can be labeled significant when a ‘nil’ hypothesis is used rather than a true ‘null’ hypothesis.” In recent years, despite its success, there is an emerging debate about whether to use p-values to describe statistically significant scientific results due to its frequent failure to reproduce and replicate similar statistically significant findings. Halsey et al5 argued that: “the p-value is often used without the realization that in most cases the statistical power of a study is too low for p to assist the interpretation of the data.… Researchers would do better to discard the p-value and use alternative statistical measures for data interpretation.” In agreement with this thinking, the journal of Basic and Applied Social Psychology recently barred p-values and hypothesis testing from articles published in their journal.6p-Values are also susceptible to “hacking,” to demonstrate statistical significance when no association exists and encourages selective reporting of only positive findings. A recent methodological review of articles published in high impact journals suggests that significant results are about twice as likely to be reported as nonsignificant results.7
In our opinion, p-values alone cannot be responsible for the lack of reproducibility of research findings, as it is often a combination of methodological errors and interpretation. Like other statistical measures, the p-value is also a one-dimensional metric and based on data; thus, it could be misleading when calculated from relatively small samples. The overall selection of statistical methods, including the lack of randomness in the sample and missing data, can also influence the statistical significance that may result in misleading p-values. Misinterpretation of the p-value as a measure of the strength of association, rather than its true meaning (assessing the probability for a given result arising due to chance), is a glaring indictment of the current biomedical teaching standards. A recent methodological survey of statistical methods in Indian journals suggests that no significant progress has been achieved regarding the correct use of statistical analyses.8
Suggested Alternatives on Statistical Significance
Several alternatives to p-values have been suggested in the literature, such as confidence intervals and Bayesian statistics.9 A confidence interval provides the point estimate with uncertainty bounds that can be more informative than a p-value. However, confidence intervals are like p-values when testing the null hypothesis's acceptance or rejection and challenging to compare between studies due to unit-dependence. In Bayesian statistics, the credible interval, equivalent to the frequentist approach's confidence interval, is another possible alternative to the p-value. Both alternative methods are like the p-value when testing the null hypothesis for clinical decision-making and can misinterpret the results' clinical or biological importance. Recently, Benjamin et al proposed to lower the p-value (the conventional “statistical significance”) threshold from 0.05 to 0.005 for all novel claims with relatively low prior odds, to avoid high false positives and improve the reproducibility of scientific research.10 However, others have argued that research should be guided by rigorous scientific principles, not by heuristics and arbitrary thresholds. These principles include sound statistical analyses, replication, validation and generalization, avoidance of logical traps, intellectual honesty, research workflow transparency, and accounting for potential sources of error.11,12
Guidance on Appropriate Interpretation of Statistical Significance
Therefore, educating researchers with appropriate training on concepts and relevant software could be one alternative to prevent misinterpretation of the p-value. It is worth reiterating Fisher’s initial view that p-values should be one part of the evidence used when deciding whether to reject the null hypothesis. Appropriate guidance should also be taken during the design, process and data analysis of a study from various available resources such as Consolidated Standards of Reporting Trials (CONSORT)13 for clinical trials, Preferred Reporting Items for Systematic reviews and Meta-Analyses (PRISMA)14 for systematic reviews and meta-analysis, Strengthening the Reporting of Observational Studies in Epidemiology (STROBE)15 for observational studies, and Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD)16 for risk prediction from a multivariable model.
As mentioned in NHST approach, researchers commonly classify results as statistically “significant” or “not-significant,” based on whether the p-value is smaller than some prespecified cut point value (usually 0.05). However, this practice is becoming obsolete, and exact p-values are preferred by leading medical journals such as the British Medical Journal (BMJ), Journal of the American Medical Association (JAMA), and the Lancet. Guidance should be taken from Fisher’s1 belief about p-values from his 1925 book and Efron’s17 interpretation on observed p-values (or achieved significance level) as presented in Table 1. The American Statistical Association (ASA) took this matter to their board in 2015 and discussed it with renowned statisticians in multiple rounds for several months. Further, a “statement on statistical significance and p-values” with six principles has been released by ASA at the beginning of 2016 to guide researchers and avoid any misuse and misinterpretation.18 In its statement, the ASA advised researchers to avoid drawing scientific conclusions or making policy decisions purely based on p-values. Additionally, they recommend describing the data analysis approach that produces statistically significant results, including all statistical tests and choices made in calculations. Otherwise, results may appear misleadingly robust.
|
Fisher’s beliefs regarding p-values |
Efron’s interpretations of achieved significance levels |
||
|---|---|---|---|
|
p-value |
Fisher’s statements |
Achieved significance levels (ASL) |
Interpretation |
|
0.1–0.9 |
Certainly, no reason to suspect the hypothesis tested |
ASL < 0.10 |
Borderline evidence against the null hypothesis |
|
0.02–0.05 |
Judged significant, though barely so … these data do not, however, demonstrate the point beyond the possibility of doubt |
ASL < 0.05 |
Reasonably strong evidence against the null hypothesis |
|
< 0.02 |
Strongly indicated that the hypothesis fails to account for the whole of the facts |
ASL < 0.025 |
Strong evidence against the null hypothesis |
|
< 0.01 |
No practical importance of whether p-value is 0.01 or 0.000001 |
ASL < 0.01 |
Very strong evidence against the null hypothesis |
Conclusion
In conclusion, we advocate that statistics should be used as a science rather than a recipe for the desired flavor. While researchers want certainty, they must understand that statistics is a science of uncertainty. Thus, solely relying on a single p-value to describe the scientific value of a study is a misuse of the p-value and when evaluating the strength of any evidence, researchers need to explain their results in the light of theoretical considerations such as scope, explanatory extent, and predictive power.
Conflict of Interest
None declared.
References
- 1925. Statistical Methods for Research Workers 1st edition. London: Oliver and Boyd
- 2008. p. :1-22. The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice, and Lives. Ann Arbor, MI: University of Michigan Press
- The fickle P value generates irreproducible results. Nat Methods. 2015;12(03):179-185.
- [Google Scholar]
- The distribution of P-values in medical research articles suggested selective reporting associated with statistical significance. J Clin Epidemiol. 2017;87:70-77.
- [Google Scholar]
- Research design and statistical methods in Indian medical journals: a retrospective survey. PLoS One. 2015;10(04):e0121268.
- [Google Scholar]
- CONSORT 2010 statement: updated guidelines for reporting parallel group randomised trials. BMJ. 2010;340:c332.
- [Google Scholar]
- Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. PLoS Med. 2009;6(07):e1000097.
- [Google Scholar]
- The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies. Lancet. 2007;370:1453-1457. (9596)
- [Google Scholar]
- Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD): the TRIPOD statement. Br J Surg. 2015;102(03):148-158.
- [Google Scholar]
- 1993. An Introduction to the Bootstrap 1st edition. New York: Chapman & Hall
- The ASA statement on p-values: context, process, and purpose. Am Stat. 2016;70(02):129-133.
- [Google Scholar]




